Googleスプレッドシートでホームページからデータを取得する
ホームページをリニューアルする際に、現在のホームページの構成がどのようになっているか?を調べる必要があります。
ページ数が少ない場合はマンパワーでできますが、ページ数が多いホームページの場合は、マンパワーだと時間もかかり、見落としもでてきたりします。
そんな時に便利なものは、Googleスプレッドシートでその調べたいホームページから「IMPORTXML関数」を使ってデータを取得する方法です。
IMPORTXML関数とは
XML 、HTML、CSV、RSSフィード、Atom、XMLフィードなど、さまざまな種類の構造化データをインポートできる関数です。
関数は
=IMPORTXML(参照セル,"XPath クエリ")と記載すると実行されます。
なお、「XPath クエリ」には取得したい階層を入力します。
URLの一覧からすべてのページタイトルを一気に取得
- セルA1にデータを取得したいホームページのURLを入力します。
- リンクURLをB列、リンクのテキストをC列に出力する場合、セルB1に「=IMPORTXML(A1,"//a/@href")」、セルC1には「=IMPORTXML(A1,"//a")」を入力します。
- 関数が実行されると、セルA1に入力したホームページのリンクURL・リンクテキストすべてが、それぞれB列・C列に表示されます。
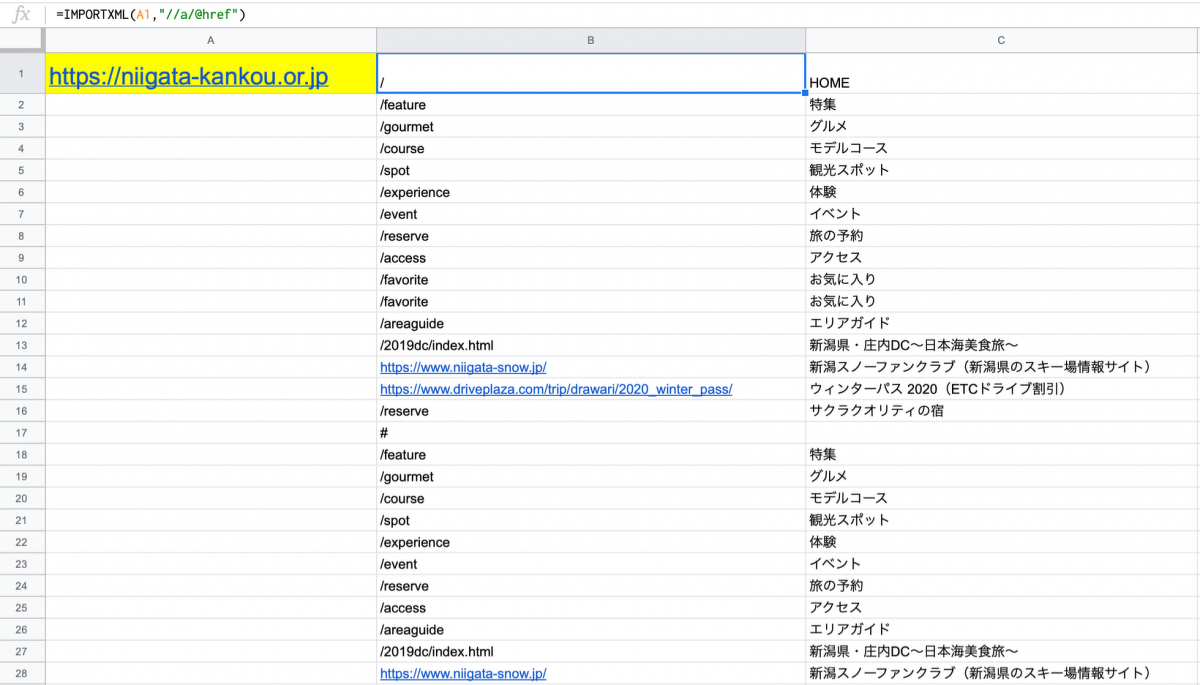
↑新潟県観光協会ホームページのトップページのURLを調査したもの
ただし、上記の場合は「セルA1」に入れたページからリンクしているディレクトリ・ページが表示されており、「セルA1」に入れたページからリンクが貼られていないディレクトリ・ページがあると、ここには表示されません。
また、この関数はHTMLソースを上からなめていくため、ホームページの上部にあるリンクと、下部にあるリンクで同じリンク先がある場合は、B列に同じ内容が表示されます。